附录 3: 其他技术信息#
本节介绍各种技术主题,这些主题不一定相互关联。
图像变换矩阵#
从版本 1.18.11 开始,文本和图像提取的一些方法会返回图像变换矩阵:Page.get_text() 和 Page.get_image_bbox()。
变换矩阵包含图像如何变换以适应文档页面上的矩形(其“边界框”=“bbox”)的信息。通过检查页面上图像的 bbox 和此矩阵,可以确定例如图像在页面上是否缩放或旋转显示以及如何显示。
图像尺寸与其在页面上的 bbox 之间的关系如下
- 使用原始图像的宽度和高度,
定义图像矩形
imgrect = pymupdf.Rect(0, 0, width, height)定义“收缩矩阵”
shrink = pymupdf.Matrix(1/width, 0, 0, 1/height, 0, 0)。
使用其收缩矩阵变换图像矩形,将得到单位矩形:
imgrect * shrink = pymupdf.Rect(0, 0, 1, 1)。使用图像**变换矩阵**“transform”,以下步骤将计算 bbox
imgrect = pymupdf.Rect(0, 0, width, height) shrink = pymupdf.Matrix(1/width, 0, 0, 1/height, 0, 0) bbox = imgrect * shrink * transform
检查矩阵乘积
shrink * transform将揭示图像矩形如何变换以适应页面上 bbox 的所有信息:旋转、边缩放和原点平移。让我们看一个例子>>> imginfo = page.get_images()[0] # get an image item on a page >>> imginfo (5, 0, 439, 501, 8, 'DeviceRGB', '', 'fzImg0', 'DCTDecode') >>> #------------------------------------------------ >>> # define image shrink matrix and rectangle >>> #------------------------------------------------ >>> shrink = pymupdf.Matrix(1 / 439, 0, 0, 1 / 501, 0, 0) >>> imgrect = pymupdf.Rect(0, 0, 439, 501) >>> #------------------------------------------------ >>> # determine image bbox and transformation matrix: >>> #------------------------------------------------ >>> bbox, transform = page.get_image_bbox("fzImg0", transform=True) >>> #------------------------------------------------ >>> # confirm equality - permitting rounding errors >>> #------------------------------------------------ >>> bbox Rect(100.0, 112.37525939941406, 300.0, 287.624755859375) >>> imgrect * shrink * transform Rect(100.0, 112.375244140625, 300.0, 287.6247253417969) >>> #------------------------------------------------ >>> shrink * transform Matrix(0.0, -0.39920157194137573, 0.3992016017436981, 0.0, 100.0, 287.6247253417969) >>> #------------------------------------------------ >>> # the above shows: >>> # image sides are scaled by same factor ~0.4, >>> # and the image is rotated by 90 degrees clockwise >>> # compare this with pymupdf.Matrix(-90) * 0.4 >>> #------------------------------------------------
PDF 基本 14 字体#
以下 14 个内置字体名称**必须由每个 PDF 阅读器应用程序支持**。它们以字典形式提供,将它们的完整名称及其小写缩写映射到完整的字体基本名称。在 PyMuPDF 中需要提供**字体名称**的地方,可以使用字典中的任何**键或值**
In [2]: pymupdf.Base14_fontdict
Out[2]:
{'courier': 'Courier',
'courier-oblique': 'Courier-Oblique',
'courier-bold': 'Courier-Bold',
'courier-boldoblique': 'Courier-BoldOblique',
'helvetica': 'Helvetica',
'helvetica-oblique': 'Helvetica-Oblique',
'helvetica-bold': 'Helvetica-Bold',
'helvetica-boldoblique': 'Helvetica-BoldOblique',
'times-roman': 'Times-Roman',
'times-italic': 'Times-Italic',
'times-bold': 'Times-Bold',
'times-bolditalic': 'Times-BoldItalic',
'symbol': 'Symbol',
'zapfdingbats': 'ZapfDingbats',
'helv': 'Helvetica',
'heit': 'Helvetica-Oblique',
'hebo': 'Helvetica-Bold',
'hebi': 'Helvetica-BoldOblique',
'cour': 'Courier',
'coit': 'Courier-Oblique',
'cobo': 'Courier-Bold',
'cobi': 'Courier-BoldOblique',
'tiro': 'Times-Roman',
'tibo': 'Times-Bold',
'tiit': 'Times-Italic',
'tibi': 'Times-BoldItalic',
'symb': 'Symbol',
'zadb': 'ZapfDingbats'}
与其强制要求相反,并非所有 PDF 阅读器都能正确完整地支持这些字体—— Symbol 和 ZapfDingbats 尤其如此。此外,字形(视觉)图像将特定于每个阅读器。
要查看如何使用这些字体——包括 **CJK 内置**字体——请参阅 Page.insert_font() 中的表格。
Adobe PDF 参考#
本文档中经常引用 Adobe 发布的这本 PDF 参考手册。可以在 opensource.adobe.com 查看和下载。
在 PyMuPDF 中使用 Python 序列作为参数#
当 PyMuPDF 对象和方法需要 Python **列表**形式的数值时,也允许使用其他 Python **序列类型**。如果 Python 类具有 __getitem__() 方法,则称其实现了**序列协议**。
这基本上意味着,在这些情况下,你可以互换使用 Python list 或 tuple,甚至 array.array、numpy.array 和 bytearray 类型。
例如,通过以下任一方式指定序列 "s"
s = [1, 2]– 一个列表s = (1, 2)– 一个元组s = array.array("i", (1, 2))– 一个 array.arrays = numpy.array((1, 2))– 一个 numpy 数组s = bytearray((1, 2))– 一个 bytearray
将使其在以下示例表达式中可用
pymupdf.Point(s)pymupdf.Point(x, y) + sdoc.select(s)
类似地,所有几何对象 Rect、IRect、Matrix 和 Point 也是如此。
因为所有 PyMuPDF 几何类本身就是序列的特例,所以它们(除了 Quad – 见下文)可以在可以使用数值序列的地方自由使用,例如作为 list()、tuple()、array.array() 或 numpy.array() 等函数的参数。请看下面的代码片段了解其工作原理。
>>> import pymupdf, array, numpy as np
>>> m = pymupdf.Matrix(1, 2, 3, 4, 5, 6)
>>>
>>> list(m)
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0]
>>>
>>> tuple(m)
(1.0, 2.0, 3.0, 4.0, 5.0, 6.0)
>>>
>>> array.array("f", m)
array('f', [1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
>>>
>>> np.array(m)
array([1., 2., 3., 4., 5., 6.])
注意
Quad 也是一个 Python 序列对象,长度为 4。但其元素是 point_like – 而非数字。因此,上述说明不适用。
确保 PyMuPDF 中重要对象的一致性#
PyMuPDF 是 C 语言库 MuPDF 的 Python 绑定。虽然 MuPDF 的创建者投入了大量精力来模仿某种程度的面向对象行为,但在这方面,他们无疑无法克服 C 语言的基本缺陷。
另一方面,Python 以非常干净的方式实现了 OO 模型。PyMuPDF 和 MuPDF 之间的接口代码由两个基本文件组成:pymupdf.py 和 fitz_wrap.c。它们由出色的 SWIG 工具为每个新版本创建。
当你使用 PyMuPDF 的对象或方法时,这将导致执行 pymupdf.py 中的一些代码,这些代码反过来会调用用 fitz_wrap.c 编译的一些 C 代码。
因为 SWIG 在保持 Python 和 C 级别同步方面做了很多工作,如果严格遵循一套规则,一切都会正常工作。例如:在你关闭(或删除或设置为 None)拥有该 Page 的 Document 后,**绝不要访问**该 Page 对象。或者,不太明显的是:在你执行了文档方法 select()、delete_page()、insert_page()……等之后,**绝不要访问**页面或其任何子对象(链接或注解)。
但仅仅不再访问无效对象实际上是不够的:应该积极地完全删除它们,以便同时释放 C 级别的资源(即分配的内存)。
这些规则的原因在于,文档与其页面之间以及页面与其链接/注解之间存在两级一对多的层级关系。为了保持一致性,上述任何操作都必须导致完全重置——在 **Python 中,并同步在 C 中**。
SWIG 无法了解这一点,因此不会执行此操作。
因此,所需的逻辑已以内置方式集成到 PyMuPDF 本身中,如下所示。
如果页面“丢失”了其拥有文档或其自身被删除,则其所有当前存在的注解和链接在 Python 中将变得不可用,并且它们的 C 级别对应物将被删除和释放。
如果文档关闭(或删除或设置为
None)或其结构发生变化,则类似地,所有当前存在的页面及其子对象将变得不可用,并且将进行相应的 C 级别删除。“结构变化”包括select()、delePage()、insert_page()、insert_pdf()等方法:所有这些都将导致对象删除的级联效应。
程序员通常不会意识到这一切。但是,如果他尝试访问无效对象,将引发异常。
无效对象不能像使用 Python 语句 *del page* 或 *page = None* 等那样直接删除。相反,必须调用它们的 *__del__* 方法。
所有页面、链接和注解都有属性 *parent*,该属性指向拥有对象。这是可以在应用程序级别检查的属性:如果 *obj.parent == None*,则对象的父对象已不存在,并且对其属性或方法的任何引用都将引发异常,指示这种“孤立”状态。
示例会话
>>> page = doc[n]
>>> annot = page.first_annot
>>> annot.type # everything works fine
[5, 'Circle']
>>> page = None # this turns 'annot' into an orphan
>>> annot.type
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
>>>
>>> # same happens, if you do this:
>>> annot = doc[n].first_annot # deletes the page again immediately!
>>> annot.type # so, 'annot' is 'born' orphaned
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
这显示了级联效应
>>> doc = pymupdf.open("some.pdf")
>>> page = doc[n]
>>> annot = page.first_annot
>>> page.rect
pymupdf.Rect(0.0, 0.0, 595.0, 842.0)
>>> annot.type
[5, 'Circle']
>>> del doc # or doc = None or doc.close()
>>> page.rect
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
>>> annot.type
<... omitted lines ...>
RuntimeError: orphaned object: parent is None
注意
上述关系之外的对象不包含在此机制中。例如,如果你通过 *toc = doc.get_toc()* 创建了目录,后来关闭或更改了文档,这无法也不会以任何方式更改变量 *toc*。根据需要刷新此类变量是你的责任。
方法 Page.show_pdf_page() 的设计#
目的和功能#
此方法在当前(“包含”、“目标”)页面的指定矩形内显示另一个 PDF 文档的某个(“源”)页面的图像。
**与**
Page.insert_image()**相比**,此显示是基于矢量的,因此在不同的缩放级别下都能保持准确。**就像**
Page.insert_image()**一样**,显示的尺寸会调整到给定的矩形。
目前支持以下显示变体
- 布尔参数
"keep_proportion"控制是否保持纵横比(默认)或不保持。 矩形参数
"clip"限制源页面矩形的可见部分。默认是整个页面。
- 布尔参数
浮点数
"rotation"按任意角度(度)旋转显示。如果角度不是 90 的整数倍,并且"keep_proportion"为 True,则 4 个角中可能只有 2 个位于目标边界上。布尔参数
"overlay"控制是否将图像放在当前页面内容的顶部(前景,默认)或不放(背景)。
用例包括(但不限于)以下内容
使用相同图像(如公司徽标或水印)“盖章”当前文档的一系列页面。
将任意输入页面组合到单个输出页面,以支持“小册子”或双面打印(称为“4-up”、“n-up”)。
将(大)输入页面分割成任意多个部分。这也称为“海报化”,例如,你可以将一张 A4 页面水平和垂直分割,将这 4 个部分放大打印到单独的 A4 页面上,最终得到原始页面的 A2 版本。
技术实现#
这是通过使用 PDF **“Form XObjects”** 来完成的,参见 Adobe PDF 参考手册 第 217 页的 8.10 节。执行 Page.show_pdf_page() 时,会发生以下情况
源文档中源页面的
resources和contents对象会被复制到目标文档,共同创建一个新的 **Form XObject**,具有以下属性。此方法的返回值为该对象的 PDFxref编号。然后创建第二个 **Form XObject**,目标页面使用它来调用显示。此对象具有以下属性
/BBox等于源页面的/CropBox(或"clip")。
/Matrix表示将/BBox映射到目标矩形的关系。
/XObject通过固定名称fullpage引用前一个 Form XObject。此对象的流只包含一个固定语句:
/fullpage Do。如果提供了方法的
"oc"参数,其值将作为/OC分配给此 Form XObject。目标页面的
resources和contents对象现在修改如下。
向
/Resources的/XObject字典添加一个条目,名称为fzFrm(n 的选择确保此条目在页面上是唯一的)。根据
"overlay"参数,在页面的/Contents数组前置或后置一个新对象,该对象包含语句q /fzFrm<n> Do Q。
这种设计方法确保
(可能很大的)源页面只复制一次到目标 PDF。每个目标页面只创建小的“指针” Form XObjects 对象来显示源页面。
每个引用源页面的目标页面可以有自己的
"oc"参数来单独控制源页面的可见性。
诊断#
PyMuPDF 消息#
PyMuPDF 有一个消息系统,用于显示文本诊断信息。
默认情况下,消息会写入 sys.stdout。可以通过两种方式控制:
在导入 PyMuPDF 之前设置环境变量
PYMUPDF_MESSAGE。
MuPDF 错误和警告#
MuPDF 生成文本错误和警告。
这些错误和警告会被附加到一个内部列表,可以通过
Tools.mupdf_warnings()访问。另请参阅Tools.reset_mupdf_warnings()。默认情况下,这些错误和警告也会发送到 PyMuPDF 消息系统。
这可以通过
mupdf_display_errors()和mupdf_display_warnings()控制。这些消息分别带有前缀
MuPDF error:和MuPDF warning:。
一些 MuPDF 错误可能导致 Python 异常。
**可恢复错误**的示例输出。我们正在打开一个损坏的 PDF,但 MuPDF 能够修复它并提供一些关于发生情况的信息。然后,我们演示了如何确定文档以后是否可以增量保存。此时检查 Document.is_dirty 属性也表明在 pymupdf.open 期间文档必须被修复
>>> import pymupdf
>>> doc = pymupdf.open("damaged-file.pdf") # leads to a sys.stderr message:
mupdf: cannot find startxref
>>> print(pymupdf.TOOLS.mupdf_warnings()) # check if there is more info:
cannot find startxref
trying to repair broken xref
repairing PDF document
object missing 'endobj' token
>>> doc.can_save_incrementally() # this is to be expected:
False
>>> # the following indicates whether there are updates so far
>>> # this is the case because of the repair actions:
>>> doc.is_dirty
True
>>> # the document has nevertheless been created:
>>> doc
pymupdf.Document('damaged-file.pdf')
>>> # we now know that any save must occur to a new file
**不可恢复错误**的示例输出
>>> import pymupdf
>>> doc = pymupdf.open("does-not-exist.pdf")
mupdf: cannot open does-not-exist.pdf: No such file or directory
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
doc = pymupdf.open("does-not-exist.pdf")
File "C:\Users\Jorj\AppData\Local\Programs\Python\Python37\lib\site-packages\fitz\pymupdf.py", line 2200, in __init__
_pymupdf.Document_swiginit(self, _pymupdf.new_Document(filename, stream, filetype, rect, width, height, fontsize))
RuntimeError: cannot open does-not-exist.pdf: No such file or directory
>>>
坐标#
这是本文档中最常用的术语之一。**坐标**通常指一对数字 (x, y),用于表示某个位置,例如矩形 (Rect) 的角、Point 等。这两个值通常是浮点数,但像图像这样的对象只允许它们是整数。
要真正*找到*坐标的位置,我们还需要知道 x 和 y 的*参考*点——换句话说,我们必须知道位置 (0, 0) 在哪里。一旦 (0, 0)(“原点”)已知,我们就说存在一个“坐标系”。
文档处理中存在多种坐标系。例如,PDF 页面的坐标系与从中创建的图像的坐标系**不同**。因此,我们需要将坐标从一个系统*变换*到另一个系统(偶尔也变换回来)的方法。这是 Matrix 的任务。它是一个数学函数,其工作方式很像一个因子,可以与点或矩形“相乘”,从而在另一个坐标系中给出相应的点/矩形。变换矩阵的逆可以用来恢复变换。这很像乘以某个因子(比如 3)可以通过将结果除以 3(或乘以 1/3)来恢复。
坐标和图像#
图像具有整数坐标的坐标系。原点 (0, 0) 是左上角点。x 值必须在 range(width) 范围内,而 y 值必须在 range(height) 范围内。因此,如果我们*向下*移动,y 值会*增加*。对于每张图像,只有**有限数量**的坐标,即 width * height。图像中的一个位置也称为“像素”。
图像打印时会有多**大**(以厘米或英寸为单位),取决于附加信息:“分辨率”。这以 **DPI**(每英寸点数,或每英寸像素)衡量。因此,要找到图像的打印尺寸,我们必须将其宽度和高度除以相应的 DPI 值(宽度和高度可能分别有不同的 DPI 值),即可得到相应的英寸数。
原点、点尺寸和 Y 轴#
在 PDF 中,页面的原点 (0, 0) 位于其**左下角**。在 MuPDF 中,页面的原点 (0, 0) 位于其**左上角**。
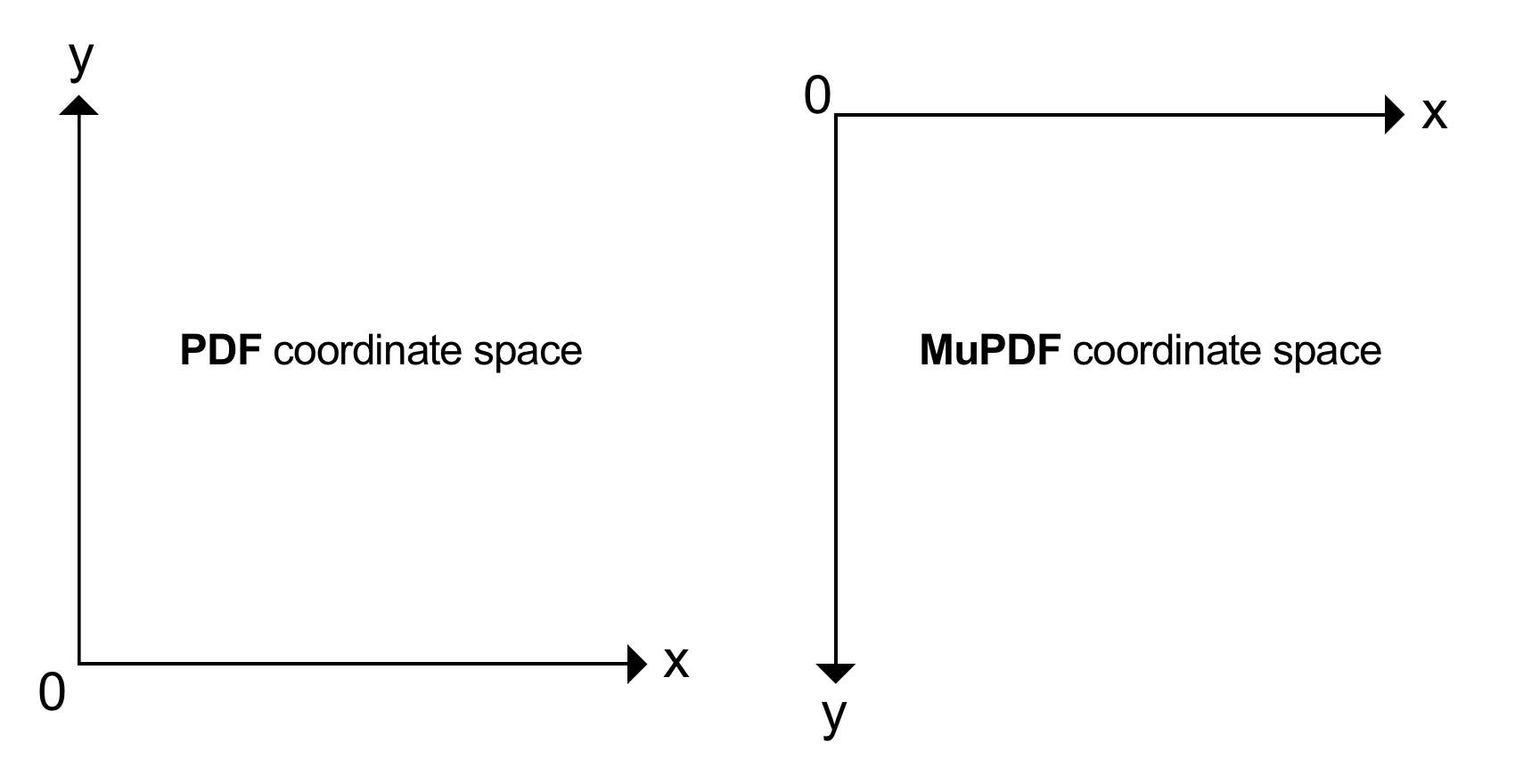
坐标是浮点数,以**点**为单位衡量,其中
一点等于 1/72 英寸.
典型的文档页面尺寸有 **ISO A4** 和 **Letter**。一个 **Letter** 页面的尺寸是 **8.5 x 11 英寸**,对应于 **612 x 792 点**。在 PDF 坐标系中,**Letter** 页面的左上角点因此具有坐标 (0, 792),因为 **Y 轴指向上方**。现在我们知道文档尺寸,MuPDF 坐标系中右下角的坐标将是 (612, 792)(而在 PDF 中,此坐标将是 (612,0))。
理论上,PDF 页面上有**无限多**的坐标位置。然而在实践中,最多前 5 位小数足以满足合理的精度。
在 MuPDF 中,支持多种文档格式 - PDF 只是**十几种其他格式**之一。MuPDF 也支持将图像作为文档(因此通常只有一个页面)。这是 MuPDF 使用原点
(0, 0)为任何文档页面**左上角**的坐标系的原因之一。**Y 轴指向下方**,就像图像一样。无论如何,MuPDF 中的坐标是浮点数,就像 PDF 中一样。例如,在 MuPDF(因此也是 PyMuPDF)中,一个矩形
Rect(0, 0, 100, 100)是一个边长为 100 点(= 1.39 英寸或 3.53 厘米)的正方形。其左上角是原点。要在 PDF 和 MuPDF 这两个坐标系之间切换,每个 Page 对象都有一个Page.transformation_matrix。其逆可以用来计算矩形的 PDF 坐标。通过这种方式,我们可以方便地发现 MuPDF 中的Rect(0, 0, 100, 100)与 PDF 中的Rect(0, 692, 100, 792)相同。请参阅此代码片段>>> page = doc.new_page(width=612, height=792) # make new Letter page >>> ptm = page.transformation_matrix >>> # the inverse matrix of ptm is ~ptm >>> pymupdf.Rect(0, 0, 100, 100) * ~ptm Rect(0.0, 692.0, 100.0, 792.0)
脚注