TextPage#
此类表示文档页面上显示的文本和图像。支持所有MuPDF 文档类型。
创建 textpage 的常用方法是 DisplayList.get_textpage() 和 Page.get_textpage()。由于此类中的方法集有限,Page 中存在更易于使用的包装器。此表的最后一列显示了这些对应的 Page 方法。
有关此类详细描述,请参见附录 2。
方法 |
描述 |
page.get_text 或 search 方法 |
|---|---|---|
提取纯文本 |
“text” |
|
上一个的同义词 |
“text” |
|
按块分组的纯文本 |
“blocks” |
|
所有单词及其 bbox |
“words” |
|
HTML 格式的页面内容 |
“html” |
|
XHTML 格式的页面内容 |
“xhtml” |
|
XML 格式的页面文本 |
“xml” |
|
dict 格式的页面内容 |
“dict” |
|
JSON 格式的页面内容 |
“json” |
|
dict 格式的页面内容 |
“rawdict” |
|
JSON 格式的页面内容 |
“rawjson” |
|
在页面中搜索字符串 |
类 API
- class TextPage#
- extractText(sort=False)#
- extractTEXT(sort=False)#
返回页面完整文本的字符串。文本是 UTF-8 unicode 编码,顺序与文档创建时指定的顺序相同。
- 参数:
sort (bool) – (v1.19.1 新增)按垂直方向然后按水平方向坐标对输出进行排序。在许多情况下,这足以生成“自然”的阅读顺序。
- 返回类型:
str
- extractBLOCKS()#
Textpage 内容以按块分组的文本行列表形式表示。每个列表项看起来像这样
(x0, y0, x1, y1, "lines in the block", block_no, block_type)
前四个条目是块的 bbox 坐标,block_type 对于图像块是 1,对于文本块是 0。block_no 是块的序列号。多行文本通过换行符连接。
对于图像块,包含其 bbox 和包含一些图像元信息的文本行 – 不包含图像内容。
这是一种高速方法,仅包含足够的信息以按所需的阅读顺序输出纯文本。
- 返回类型:
list
- extractWORDS(delimiters=None)#
在 v1.23.5 中更改:新增
delimiters参数
Textpage 内容以带有 bbox 信息的单个单词列表形式表示。此列表中的一项看起来像这样
(x0, y0, x1, y1, "word", block_no, line_no, word_no)
- 参数:
delimiters (str) – (v1.23.5 新增)使用这些字符作为额外的单词分隔符。默认情况下,所有空白字符(包括非换行空格
0xA0)表示单词的开始和结束。现在您可以指定更多字符来导致此行为。例如,默认情况下会返回"john.doe@outlook.com"作为一个单词。如果您指定delimiters="@.",则会返回四个单词:"john"、"doe"、"outlook"、"com"。其他可能的用法包括忽略标点符号delimiters=string.punctuation。“word”字符串将不包含任何分隔字符。
这是一种高速方法,例如可以从给定区域内提取文本或恢复文本阅读顺序。
- 返回类型:
list
- extractHTML()#
Textpage 内容以 HTML 格式字符串形式表示。此版本包含完整的格式和定位信息。包含图像(编码为 base64 字符串)。您需要一个 HTML 包来在 Python 中解释输出。您的互联网浏览器应该能够充分显示此信息,但请参见控制 HTML 输出质量。
- 返回类型:
str
- extractDICT(sort=False)#
Textpage 内容以 Python 字典形式表示。提供与 HTML 相同的信息详细程度。请参阅下面的结构。
- 参数:
sort (bool) – (v1.19.1 新增)按垂直方向然后按水平方向坐标对输出进行排序。在许多情况下,这足以生成“自然”的阅读顺序。
- 返回类型:
dict
- extractJSON(sort=False)#
Textpage 内容以 JSON 字符串形式表示。由
json.dumps(TextPage.extractDICT())创建。包含此方法是为了向后兼容。您可能只会将此方法用于将结果输出到文件。该方法检测二进制图像数据并将其转换为 base64 编码字符串。- 参数:
sort (bool) – (v1.19.1 新增)按垂直方向然后按水平方向坐标对输出进行排序。在许多情况下,这足以生成“自然”的阅读顺序。
- 返回类型:
str
- extractXHTML()#
Textpage 内容以 XHTML 格式字符串形式表示。文本信息详细程度与
extractTEXT()相似,但包含图像(base64 编码)。此方法不尝试重新创建原始视觉外观。- 返回类型:
str
- extractXML()#
Textpage 内容以 XML 格式字符串形式表示。这包含页面上每个字符的完整格式信息:字体、大小、行、段落、位置、颜色等。不包含图像。您需要一个 XML 包来在 Python 中解释输出。
- 返回类型:
str
- extractRAWDICT(sort=False)#
Textpage 内容以 Python 字典形式表示 – 技术上类似于
extractDICT(),并且包含其信息作为子集(包括任何图像)。它提供了每个字符的额外详细信息,这使得在许多情况下使用 XML 变得过时。请参阅下面的结构。- 参数:
sort (bool) – (v1.19.1 新增)按垂直方向然后按水平方向坐标对输出进行排序。在许多情况下,这足以生成“自然”的阅读顺序。
- 返回类型:
dict
- extractRAWJSON(sort=False)#
Textpage 内容以 JSON 字符串形式表示。由
json.dumps(TextPage.extractRAWDICT())创建。您可能只会将此方法用于将结果输出到文件。该方法检测二进制图像数据并将其转换为 base64 编码字符串。- 参数:
sort (bool) – (v1.19.1 新增)按垂直方向然后按水平方向坐标对输出进行排序。在许多情况下,这足以生成“自然”的阅读顺序。
- 返回类型:
str
- search(needle, quads=False)#
在 v1.18.2 中更改
搜索字符串并返回找到位置的列表。
- 参数:
needle (str) – 要搜索的字符串。如果 needle 仅包含 ASCII 字母,则大小写均匹配 – 对于“Ä”与“ä”等情况尚不适用。
quads (bool) – 返回四边形而非矩形。
- 返回类型:
list
- 返回值:
一个 Rect 或 Quad 对象列表,每个对象围绕一个找到的 needle 出现。由于搜索字符串可能包含空格,其部分可能位于不同的行上。在这种情况下,返回多个矩形(或四边形)。(在 v1.18.2 中更改)此方法现在支持去除连字符,因此即使单词“method”被分割为两部分“meth-”和“od”跨越两行,它也能找到该单词。返回的两个矩形将包含“meth”(无连字符)和“od”。
注意
v1.18.2 中的更改概述
hit_max参数已移除:始终返回所有匹配项。Rect 参数在 TextPage 中现在受尊重:仅检查此区域内的文本。只考虑 bbox 完全包含的字符。包装方法
Page.search_for()相应地支持 clip 参数。现在可以找到带有连字符的单词。
同一行中重叠的矩形现在自动合并。我们假定此类分隔是由于包含相同搜索目标部分的多个标记内容组创建的伪影。
Quad 与 Rect 的示例:当搜索目标“pymupdf”时,相应的条目将是蓝色矩形,或者如果指定了 quads,则为四边形 Quad(ul, ur, ll, lr)。

- rect#
与 text page 关联的矩形。这等于创建页面的矩形,或者
Page.get_textpage()以及文本提取/搜索方法的clip参数。注意
文本搜索和大多数文本提取的输出仅限于此矩形。(X)HTML 和 XML 输出始终提取整页。
字典输出的结构#
方法 TextPage.extractDICT()、TextPage.extractJSON()、TextPage.extractRAWDICT() 和 TextPage.extractRAWJSON() 返回字典,其中包含页面的文本和图像内容。这四种方法的字典结构几乎相同。它们力求尽可能精确地映射 text page 的块、行、span 和字符信息层级结构,通过用各自的子字典表示每一个元素
一个 page 由一个块字典列表组成。
一个(文本)block 由一个行字典列表组成。
一个 line 由一个span 字典列表组成。
一个 span 包含文本本身,或者对于 RAW 变体,包含一个字符字典列表。
RAW 变体:一个字符是一个包含其 origin、bbox 和 unicode 的字典。
此处所有 PyMuPDF 几何对象(点、矩形、矩阵)均以其 “like” 格式表示:使用 rect_like 元组代替 Rect 等。这样做的原因是出于性能和内存考虑
此代码是用 C 编写的,在 C 中可以轻松生成 Python 元组。而几何对象仅在 Python 源代码中定义。将每个 Python 元组转换为其相应的几何对象将显著增加 – 而且在很大程度上不必要 – 执行时间。
一个 4 元组大约需要 168 字节,相应的 Rect 需要 472 字节 - 几乎是三倍大小。一个包含大量文本页面的“dict”字典包含 300 多个 bbox 对象 – 因此需要大约 50 KB 的 4 元组存储空间,而 Rect 对象需要 140 KB。然而,对于这样的页面,“rawdict”输出将包含 4 到 5 千个 bbox,因此在这种情况下,存储空间为 750 KB 对比 2 MB。
另请注意,仅返回 bboxes(= rect_like 4 元组),而 TextPage 实际上具有完整的定位信息 – 以 Quad 格式。此决策的原因同样是内存考虑:一个 quad_like 需要 488 字节(是 rect_like 大小的 3 倍)。考虑到生成的 bbox 数量,返回 quad_like 信息将产生显著影响。
在绝大多数情况下,我们只处理水平文本,此时 bbox 提供的信息完全足够。
此外,完整的四边形信息并未丢失:可以通过使用以下列表中的相应函数,根据需要为行、span 和字符恢复该信息
recover_quad()– 完整 span 的四边形recover_span_quad()– span 中字符子集的四边形recover_line_quad()– 一行的四边形recover_char_quad()– 一个字符的四边形
如前所述,仅当文本不是水平书写 – line["dir"] != (1, 0) – 且您需要使用四边形进行文本标记注释(Page.add_highlight_annot() 等)时,才需要使用这些函数。
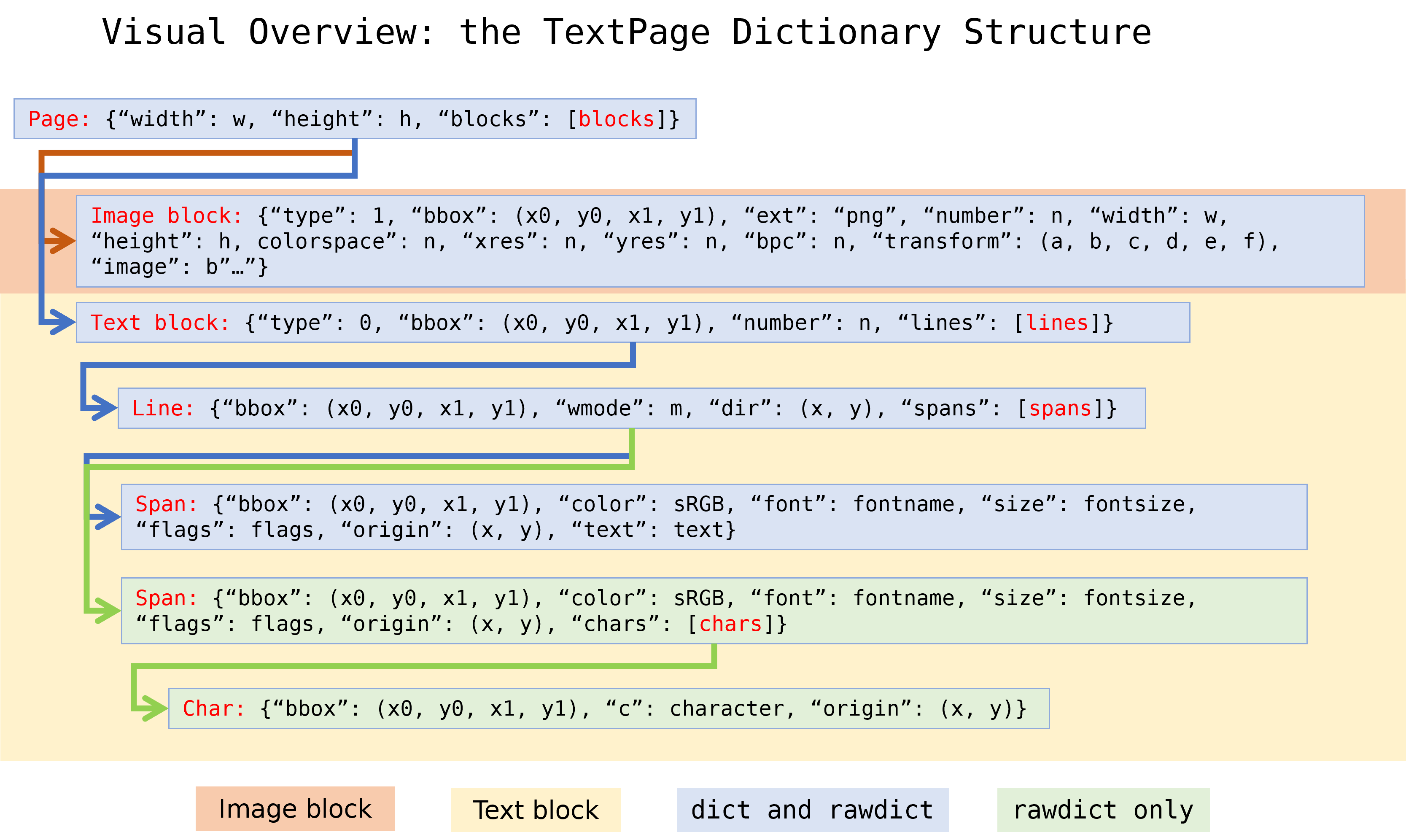
Page 字典#
键 |
值 |
|---|---|
width |
|
height |
|
blocks |
block 字典的 list |
Block 字典#
Block 字典对于图像块和文本块有两种不同的格式。
图像块
键 |
值 |
|---|---|
type |
1 = 图像 ( |
bbox |
页面上的图像 bbox ( |
number |
块计数 ( |
ext |
图像类型 ( |
width |
原始图像宽度 ( |
height |
原始图像高度 ( |
colorspace |
colorspace 分量计数 ( |
xres |
x 方向分辨率 ( |
yres |
y 方向分辨率 ( |
bpc |
每分量位数 ( |
transform |
将图像矩形转换为 bbox 的矩阵 ( |
size |
图像大小(字节)( |
image |
图像内容 ( |
mask |
透明图像的图像蒙版内容 ( |
“ext” 键的可能值为“bmp”、“gif”、“jpeg”、“jpx” (JPEG 2000)、“jxr” (JPEG XR)、“png”、“pnm”和“tiff”。
注意
对于页面上所有和每一个图像出现都会生成一个图像块。因此,如果一个图像在不同位置显示,可能会出现重复项。
TextPage 和相应的方法
Page.get_text()适用于所有文档类型。仅对于 PDF 文档,方法Document.get_page_images()/Page.get_images()在图像列表方面提供了一些重叠的功能。但这两个列表可能包含也可能不包含相同的项目。任何差异很可能由以下原因之一造成PDF 页面的“内联”图像(参见 Adobe PDF 参考手册 第 214 页)包含在 textpage 中,但不出现在
Page.get_images()中。注释也可能包含图像 – 这些图像将不出现在
Page.get_images()中。textpage 中的图像块是为每一个图像位置生成的 – 无论是否存在重复项。这与
Page.get_images()不同,后者每个引用名称只列出每个图像一次。页面
object定义中提到的图像总是出现在Page.get_images()中 [1]。但可能出现的情况是,页面的contents中没有“显示”命令(错误或有意)。在这种情况下,图像将不出现在 textpage 中。
图像的“变换矩阵”定义为满足表达式
bbox / transform == pymupdf.Rect(0, 0, 1, 1)为真的矩阵,详细信息请参见此处:图像变换矩阵。透明图像可能伴随一个蒙版图像。这存储在键
"mask"下,格式为DeviceGrayPNG 图像。否则此键的值为None。如果存在,您可以通过分别使用“image”和“mask”的值创建 Pixmap 对象并叠加它们来恢复原始图像(或其等效形式) – 即带有透明度的图像。但这不保证始终有效,因为蒙版图像有多种格式,并非所有格式都符合支持叠加 Pixmap 的条件。这里有一个代码片段
>>> base = pymupdf.Pixmap(block["image"])
>>> mask = pymupdf.Pixmap(block["mask"])
>>> result = pymupdf.Pixmap(base, mask)
文本块
键 |
值 |
|---|---|
type |
0 = 文本 (int) |
bbox |
块矩形, |
number |
块计数 (int) |
lines |
文本行字典的 list |
Line 字典#
键 |
值 |
|---|---|
bbox |
行矩形, |
wmode |
书写模式 (int): 0 = 水平, 1 = 垂直 |
dir |
书写方向, |
spans |
span 字典的 list |
键 “dir” 的值是文本相对于 x 轴的角度的单位向量 dir = (cosine, -sine) [2]。请看下图:每个象限中的单词(从右上角到右下角逆时针方向)分别旋转了 30、120、210 和 300 度。

Span 字典#
Span 包含实际文本。一行仅在包含具有不同字体属性的文本时才包含多个 span。
在版本 1.14.17 中更改:Span 现在(再次)也有 bbox 键。
在版本 1.17.6 中更改:Span 现在也有 origin 键。
键 |
值 |
|---|---|
bbox |
span 矩形, |
origin |
第一个字符的 origin, |
font |
字体名称 (str) |
ascender |
字体的 ascender (float) |
descender |
字体的 descender (float) |
size |
字体大小 (float) |
flags |
字体特征 (int) |
char_flags |
字符特征 (int) |
color |
sRGB 格式的文本颜色 0xRRGGBB (int)。 |
alpha |
文本不透明度 0..255 (int)。 |
text |
(仅用于 |
chars |
(仅用于 |
显示/隐藏历史记录
(版本 1.25.3.0 新增):添加了 “alpha” 项。
(版本 1.16.0 新增): “color” 是以 sRGB (int) 格式编码的文本颜色,例如 0xFF0000 表示红色。有函数可以将此整数转换回 (r, g, b) 格式(PDF 使用 0 到 1 的浮点值)sRGB_to_pdf(),或 (R, G, B) 格式(使用 0 到 255 的整数值)sRGB_to_rgb()。
(v1.18.5 新增): “ascender” 和 “descender” 是字体属性,相对于 fontsize 1 提供。请注意,descender 是一个负值。下图显示了它与其他值和属性的关系。

这些数字可用于计算字符(或 span)的最小高度 – 与“bbox”值中提供的标准高度(实际代表行高)相对。以下代码重新计算 span bbox,使其高度为fontsize,正好适合内部文本
>>> a = span["ascender"]
>>> d = span["descender"]
>>> r = pymupdf.Rect(span["bbox"])
>>> o = pymupdf.Point(span["origin"]) # its y-value is the baseline
>>> r.y1 = o.y - span["size"] * d / (a - d)
>>> r.y0 = r.y1 - span["size"]
>>> # r now is a rectangle of height 'fontsize'
注意
上述计算可能得出更大的高度!例如,对于 OCR 文档,文本伪影的风险很高时,可能会发生这种情况。MuPDF 尝试计算出合理的 bbox 高度,这独立于 PDF 中找到的 fontsize。因此请确保 span["bbox"] 的高度大于 span["size"]。
注意
您可以通过执行 pymupdf.TOOLS.set_small_glyph_heights(True) 请求 PyMuPDF 自动执行上述所有操作。这将设置一个全局参数,以便所有后续的文本搜索和文本提取都在有意义的情况下基于减小的字形高度。
下图显示了红色的原始 span 矩形和蓝色重新计算高度后的矩形。

“flags” 是一个整数,表示除第一个位 0 之外的字体属性。它们的解释如下
位 0:上标 (
TEXT_FONT_SUPERSCRIPT) – 不是字体属性,由 MuPDF 代码检测。位 1:斜体 (
TEXT_FONT_ITALIC)位 2:衬线 (
TEXT_FONT_SERIFED)位 3:等宽 (
TEXT_FONT_MONOSPACED)位 4:粗体 (
TEXT_FONT_BOLD)
按如下方式测试这些特征
>>> if flags & pymupdf.TEXT_FONT_BOLD & pymupdf.TEXT_FONT_ITALIC:
print(f"{span['text']=} is bold and italic")
位 1 到 4 是字体属性,即编码在字体程序中。请注意,此信息不一定正确或完整:字体通常包含错误的数据。
“char_flags” 是一个整数,表示额外的字符属性
位 0:删除线。
位 1:下划线。
位 2:合成 (synthetic)(始终为 0,参见字符字典)。
位 3:填充。
位 4:描边。
位 5:裁剪。
例如,如果没有填充且没有描边(if not (char_flags & 2**3 & 2**4): ...),则文本将不可见。
(char_flags 在 v1.25.2 中新增。)
extractRAWDICT() 的字符字典#
键 |
值 |
|---|---|
origin |
字符的左基线点, |
bbox |
字符矩形, |
synthetic |
布尔值。 |
c |
字符 (unicode) |
(synthetic 在 v1.25.3 中新增。)
此图显示了字符的 bbox 与其四边形之间的关系:
脚注